본 포스팅은 원문을 공부하기 위해 번역한 포스팅이며 오역이 있을 수 있습니다.
원문 : https://medium.com/omio-engineering/cpu-limits-and-aggressive-throttling-in-kubernetes-c5b20bd8a718
CPU limits and aggressive throttling in Kubernetes
A deep dive into Kubernetes CPU throttling and its impact on service performance and reliability.
medium.com
어플리케이션이 헬스체크 요청에 stuck 혹은 fail 상태가 되며 다른 문제를 찾지 못했습니까? 아마도 CPU quota limit일 수 있습니다. 이 포스팅에서 설명하도록 하겠습니다.
| 요약 : CFS 버그가 패치되지 않은 커널 버전을 사용하는 경우 Kubernetes에서 CPU 제한을 제거하는 것이 좋습니다. (혹은 Kubelet에서 CFS quota를 제거) 커널에 CFS 버그가 있어 불필요한 throttling와 stalls를 유발합니다. |
Omio는 전적으로 Kubernetes를 사용합니다. 모든 워크로드(stateful/stateless)는 Google Kubernetes Engine을 사용한 Kubernetes에서 실행됩니다. 지난 6개월 동안 우리는 원인을 모르는 임의의 지연을 만났습니다. 어플리케이션이 헬스체크 단계에서 stuck 혹은 fail 응답을 보냈으며 네트워크 연결에 응답하지 않았습니다. 이것은 우리에게 큰 고민을 주었습니다.
이 기사는 다음 주제를 다룹니다.
- Container와 Kubernetes 입문
- CPU 제한 및 요청 구현 방법
- 멀티 코어 환경에서 CPU 제한 방식
- CPU 조절을 모니터링 하는 방법
- 해결하는 방법
A primer on Containers & Kubernetes
Kubernetes(이하 K8S)는 인프라 환경에서 표준이나 다름없으며 컨테이너 오케스트레이터입니다.
- Container
이전에는 Java JAR/WAR 혹은 Python Eggs/Executables와 같은 아티팩트를 작성하고 서버에 실행할 수 있도록 환경을 구성했습니다. 하지만 이를 위해서는 많은 작업이 필요합니다. 런타임(Java/Python), 파일, 장소, OS를 설치해야하며 config의 관리가 필요합니다. 이는 개발자와 시스템관리자 사이의 빈번한 갈등의 원인입니다.
Container는 그것을 바꿨습니다. 아티팩트는 컨테이너 이미지이며 프로그램 이외에 런타임에 필요한 파일 및 패키지가 사전 설치되어 있으며 바로 실행할 수 있습니다. 추가 설치 없이 다양한 서버에서 제공하고 실행할 수 있습니다. 컨테이너는 자체 샌드박스 환경에서 실행됩니다. 자체적으로 가상 네트워크 어댑터, 파일 시스템, 프로세스 계층 구조, CPU와 Memory 제한을 가지고 있습니다. 이것은 namespace라 불리는 커널의 기능입니다.
- Kubernetes
Kubernetes는 컨테이너 오케스트레이션입니다. 머신 목록을 Kubernetes에게 제공하고 " 이 컨테이너 이미지를 각각 2CPU, 3GB 램을 가진 인스턴스로 실행해줘. " 라 요청할 수 있습니다. Kubernetes는 요청에 따라 사용 가능한 리소스(CPU)를 찾고 실행하며 상태가 비정상일 경우 다시 시작하며 이미지의 버전이 변경되면 롤링업데이트를 지원하는 등 작업을 수행합니다.
기본적으로 Kubernetes는 머신을 추상화하며 모든 서버를 단일 배포 대상으로 만듭니다.

Understanding Kubernetes request and limit
이제 컨테이너와 쿠버네티스가 무엇인지 이해했습니다. 또한 여러 컨테이너가 동일한 머신위에 올라갈 수 있음을 알 수 있습니다. 이것은 flat sharing(house share와 같은 개념)과 같습니다. 큰 아파트(=머신)을 여러 테넌트(=컨테이너)와 공유합니다. Kubernetes는 임대 업자입니다. 임차인들간에 문제가 생기면 어떻게 해결해야할까요? 만약 한 명의 임차인이 반나절동안 화장실을 점령하면 어떻게 해야 할까요?
그리고 이 곳에서 문제가 발생합니다.
How Kubernetes request & limit is implemented
Kubernetes는 커널 제한을 사용하여 CPU limit을 구현합니다. 어플리케이션이 제한을 초과하면 CPU limit이 적용됩니다. Memory 요청 및 제한은 다른 방식으로 구현되어 Pod의 마지막 재시작 상태(OOM Killed)를 확인하여 감지할 수 있습니다. 그러나 K8S는 usage metric만 노출하고 cgroup 메트릭은 노출하지 않기 때문에 CPU 초과는 식별하기 쉽지 않습니다.
CPU Request

간단히 보기 위해 4코어 머신에서 어떻게 구성되는지에 대해 논의하겠습니다.
K8S는 cgroup을 사용하여 Memory 및 CPU에 대한 리소스 할당량을 제어합니다. 계층 모델이 있으며 상위에 할당 된 자원만 사용할 수 있습니다. 세부사항은 가상 파일 시스템(/sys/fs/cgroup)에 저장됩니다. 예를 들어 CPU는 '/sys/fs/cgroup/cpu, cpuacct/*' 입니다.
K8S는 cpu.share 파일을 사용하여 CPU 자원을 할당합니다. 이 경우 roo cgroup은 사용가능한 CPU 파워의 100%인 4096개를 상속받습니다. root cgroup는 자식들의 CPU 점유율을 기준으로 비례적으로 할당하며 자식들과 같은 방식으로 공유합니다. 일반적으로 Kubernetes 노드에서는 root cgroup 아래에 system.slice, user.slice, kubepods 세 개의 cgroup이 있습니다. system.slice와 user.slice는 시스템 워크로드 및 K8S를 사용하지 않는 사용자를 위해 자원을 할당하는데 사용됩니다. kubepods는 K8S를 통해 생성되어 리소스를 Pod에 할당합니다.
위의 그래표를 보면 첫 번째와 두 번째 cgroup이 각각 1024를 공유하며 Kubepod에 4096을 공유한 것을 알 수 있습니다. root에 사용 가능한 CPU 점유율이 4096개인데 실제로 점유율은 6144로 해당 값을 초과합니다. 이유는 이 값이 논리적인 값이며 Linux 스케줄러(CFS)는 값을 사용하여 CPU를 비례적으로 할당하기 때문입니다. 이 경우 두 cgroup은 각각 680(4096의 16.6%)를 할당 받고 kubepod는 나머지인 2736을 할당 받습니다. 하지만 idle 상태인 경우 처음 두 cgroup은 할당 된 모든 리소스를 사용하지 않습니다. CFS 스케줄러는 사용되지 않은 CPU 공유 낭비를 피하는 메커니즘이 있습니다. 스케줄러는 사용되지 않은 CPU를 전역으로 해제하여 더 많은 CPU 전력을 요구하는 cgroup에 할당 할 수 있도록 합니다. 모든 자녀들에게도 동일한 워크플로가 적용됩니다. 이 메커니즘을 통해 CPU 전력을 공평하게 공유할 수 있으며 아무도 다른 사람의 CPU를 사용할 수 없습니다.
CPU Limit
limit과 request에 대한 K8S 구성이 비슷해보이지만 구현적인 부분은 전혀 다릅니다. 이것은 가장 잘못 가이드되며 덜 문서화 된 부분입니다. K8S는 CFS quota 메커니즘을 이용해 제한을 구현합니다. 제한에 대한 구성은 cgroup 디렉터리의 cfs_period_us와 cfs_quota_us에 구성됩니다. 사용 가능한 CPU power가 아닌 시간을 기준으로 quota은 정해집니다. cfs_period_us는 기간을 정의하는데 사용되며 항상 100000us(100ms) 입니다. K8S에서는 이 값을 변경할 수 있지만 alpha와 feature는 그대로 사용됩니다. 스케줄러는 이 기간을 이용해 quota을 재설정합니다.
cfs_quota_us는 limit 기간에 허용된 할당량을 나타내는데 사용됩니다. 이는 us unit으로 구성되어 있으며 quota은 quota period를 초과할 수 있습니다. 즉 100ms 이상 구성할 수 있습니다. 16개의 코어를 가진 머신에 대한 두 가지 시나리오를 살펴보겠습니다.

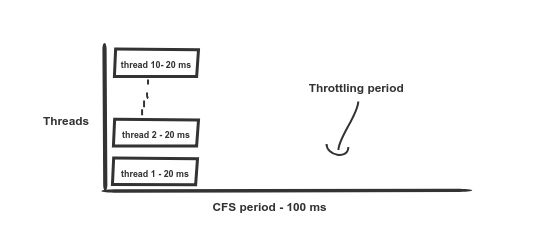
CPU Limit을 2Core로 구성했다고 가정해봅니다. K8S는 이것을 200ms로 변환합니다. 컨테이너가 제한없이 최대 200ms의 CPU time 사용할 수 있음을 의미합니다. 여기서 착오가 시작됩니다. 허용 된 할당량은 200ms입니다. 다른 pod가 idle 상태인 12개의 코어 시스템에서 10개의 병렬 스레드를 실행하는 경우 할당량은 20ms(10*20ms=200ms)를 초과합니다. 해당 Pod 아래에서 실행되는 모든 스레드는 80ms 동안 제한당합니다. 스케줄러에 불필요한 제한을 유발하고 컨테이너가 허용 된 할당량에 도달하지 못하게 하여 상황을 악화시키는 버그가 있습니다.
Checking the throttling rate of your pods
Pod에 로그인 한 다음 'cat /sys/fs/cgroup/cpu/cpu.stat'을 실행합니다.

- nr_period : 총 스케줄 기간
- nr_throttled : nr_period 도중 총 throttled 기간
- throttled_time : ns(아마도 namespace)에서 총 throttled 시간
So what really happens?
우리의 여러 어플리케이션이 높은 throttled 속도로 끝납니다. 한계치보다 50% 더 높습니다! 이는 readiness probe failures, container stalls, network disconnections, timeout service calls 등 다양한 오류로 이어지며 오류율이 높아집니다.
Fix and Impact
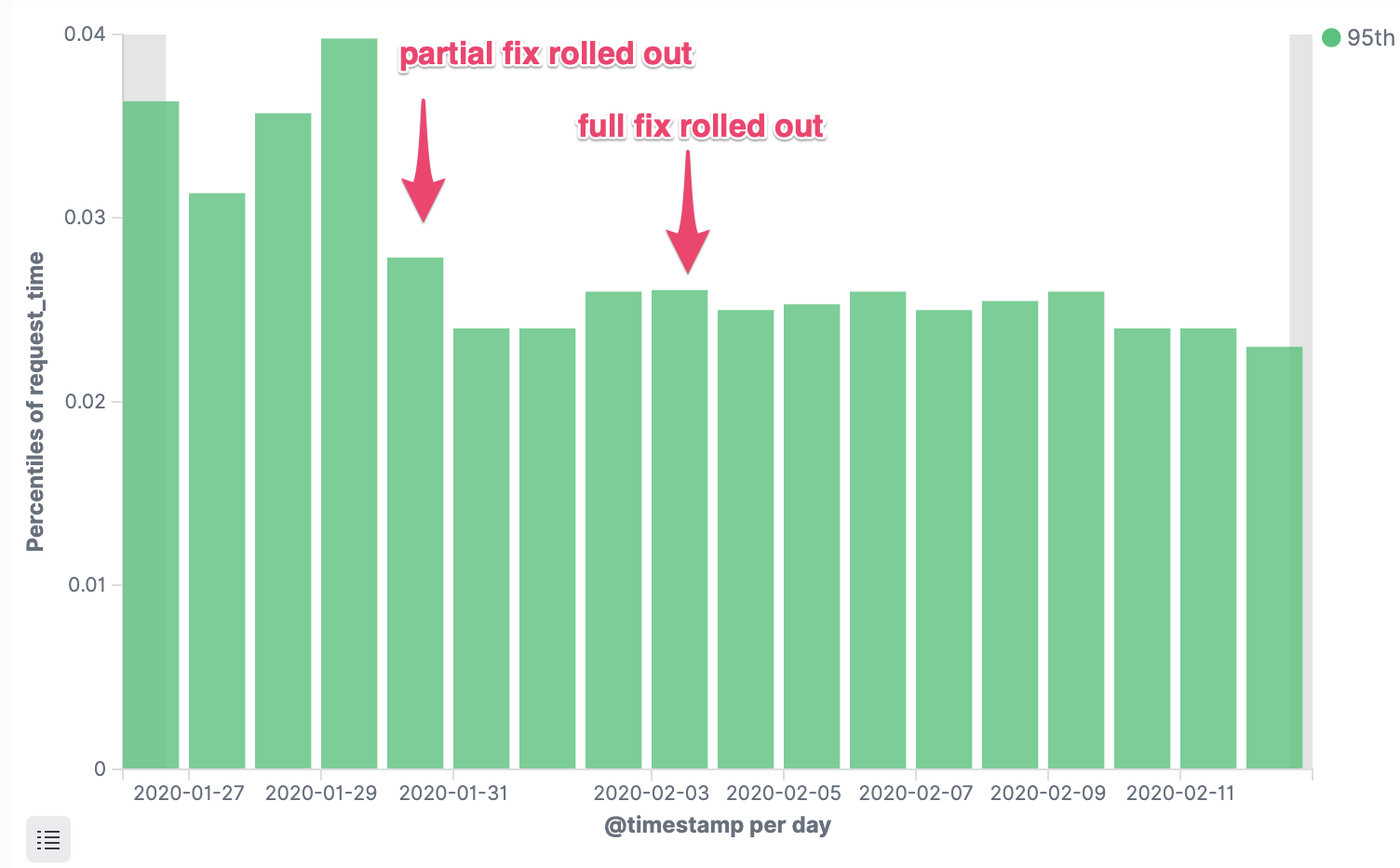
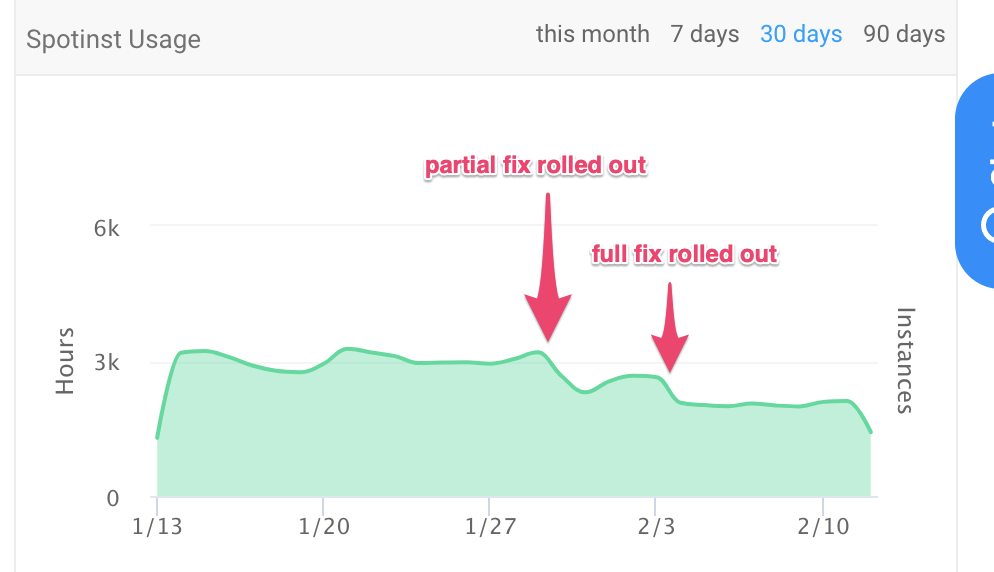
단순하게 버그가 해결된 최신 커널이 모든 클러스터에 배포될 때까지 CPU limit을 비활성화하였습니다. 즉시 서비스의 오류율이 크게 감소했습니다.
- HTTP Erro Rates (5xx)

- p95 Response time
- Utilization costs
What's the catch?
우리는 첫 부분에서 말했습니다.
| 이것은 flat sharing과 같습니다. Kubernetes는 임대인입니다. 하지만 임차인들이 서로 생긴 문제를 해결하려면 어떻게 해야할까요? 그들 중 하나가 반나절동안 화장실을 점령하면 어떻게 될까요? |
일부 컨테이너는 머신의 모든 CPU를 점유 할 위험이 있다는 것을 알아야 합니다. 적절한 어플리케이션 스택이 있는 경우 문제가 되지 않으며 오랫동안 사용할 수 있습니다. 하지만 최적화에 문제가 있거나 잘못된 어플리케이션의 경우 문제점을 야기할 수 있습니다. Omio에서는 기본 언어 스택에 대해 기본 Dockerfile을 자동화했으므로 이는 문제가 되지 않습니다. USE(Utilization, Saturation and Errors) 지표, API 대기시간, API 오류율을 모니터링하고 결과가 예상과 일치하는지 확인하십시오.
참조문서는 다음과 같습니다.
- https://www.kernel.org/doc/Documentation/scheduler/sched-design-CFS.txt
- https://www.kernel.org/doc/Documentation/scheduler/sched-bwc.txt
- https://engineering.squarespace.com/blog/2017/understanding-linux-container-scheduling
- https://www.linuxjournal.com/content/everything-you-need-know-about-linux-containers-part-i-linux-control-groups-and-process
- https://k8s.af/ — search for cpu throttling.
- Kubernetes bug reports: https://github.com/kubernetes/kubernetes/issues/51135#issuecomment-373454012 | https://github.com/kubernetes/kubernetes/issues/67577 | https://gist.github.com/bobrik/2030ff040fad360327a5fab7a09c4ff1