♥ Pig
1.1 요구 사항
- Hadoop 2.X 이상
- Java 1.7 이상
- Python 2.7 이상 (선택)
- Ant 1.8 이상 (선택)
1.2 Apache Pig
- Hadoop을 기반으로 실행되는 오픈소스 라이브러리
- 복잡한 코드를 작성할 필요 없는 스크립팅 언어를 제공함
- SQL 유형 명령으로 작업을 만듦
- 정형 및 비정형 데이터를 사용할 수 있음
- 사용자 정의 함수(UDF) 기능을 통해 여러 언어로 Pig를 호출할 수 있음
1.3 Pig 설치
(1) 이 곳에서 다운로드 받을 수 있다. 압축해제 이후 /home/centos로 Pig를 옮긴다.

(2) pig/bin 디렉토리를 PATH에 등록한다.
vi /etc/profile
source /etc/profile
(3) 재부팅해준다.
reboot(4) dfs와 yarn을 재가동해준다.
start-dfs.sh
start-yarn.sh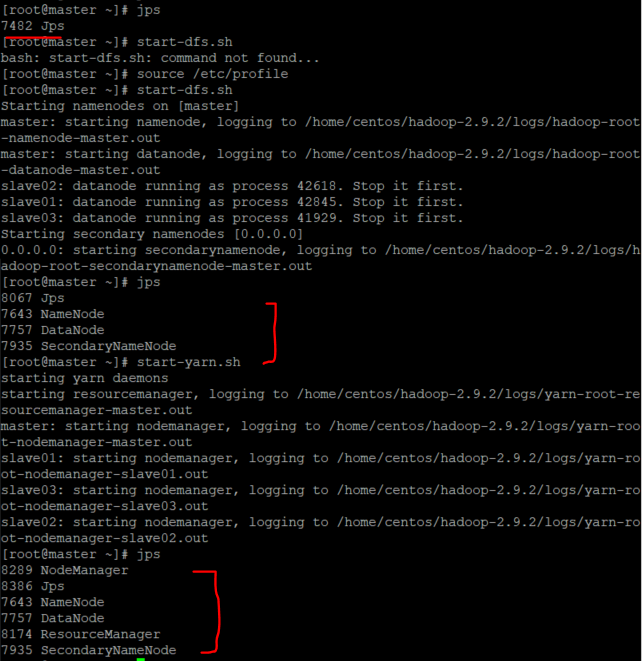
(5) jps 확인 이후 Pig를 사용하기 위해 JobHistoryServer을 켜준다.

- JobHistoryServer는 JobTracker이나 ResourceManager가 완료한 Job의 정보를 가지고 있다. Pig의 경우 작업이 끝나면 작업의 통계를 가지고 오기 때문에 History Server에 들려야 하는 것이다.
(6) Pig는 두 가지 경우로 켤 수 있다.
- 로컬 : pig -x local
- 맵리듀스 : pig -x mapreduce
노드 한 대에서 돌아가는 경우와 (로컬에서) 사용하고 있는 데이터 노드 전부에서 맵리듀스 방식으로 돌아가는 것의 차이라고 생각하면 될 것 같다.

(7) /etc/passwd 파일을 Pig로 출력 후 저장해보자
cp /etc/passwd /home/centos/data/passwd
hdfs dfs -put /home/centos/data/passwd /input
hdfs dfs -ls /input
A = LOAD '/input/passwd' using PigStorage(':');
B = FOREACH A GENERATE $0 AS id;
DUMP B;
(8) 결과를 확인한다

누가봐도 ID 부분을 뽑아왔다. 상당히 쉘 스크립트 짜는 방식과 유사하다.
(9) Output을 만들어본다.
STORE B INTO '/output/passwd'
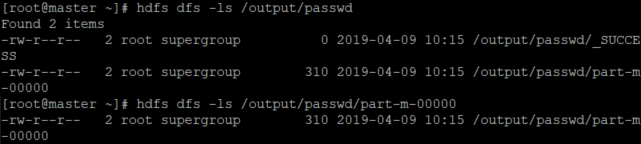
결과값이 생성된 것을 알 수 있다. 해당하는 명령어로 확인해준다.

'미분류 > Hadoop' 카테고리의 다른 글
| Hadoop - Oozie 설치하기 (0) | 2019.04.10 |
|---|---|
| Hadoop - Zookeeper 설치하기 (0) | 2019.04.10 |
| Hadoop 실습 - jar 파일을 만들어 hdfs 사용해보기 (0) | 2019.04.05 |
| VMware를 이용하여 Hadoop 완전분산모드 구축 (0) | 2019.04.04 |
| CentOS7 기반으로 Hadoop Standalone 설치하기 (0) | 2019.04.01 |



