- 노트북 주소 : (링크)
2018_korea_accident_data
Using data from [Private Dataset]
www.kaggle.com
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load in
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list the files in the input directory
import os
print(os.listdir("../input"))
# Any results you write to the current directory are saved as output.먼저 데이터가 어떤 것이 있는지부터 확인해야한다. 나는 공공 데이터 사이트에서 2018년도 교통사고 데이터를 가져왔다. 데이터가 제대로 업로드 된 것을 확인한 이후, 매핑시켜주었다.
df = pd.read_csv('../input/2018_death_data.csv',encoding='euc-kr')
df.head()
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3657 entries, 0 to 3656
Data columns (total 27 columns):
발생년 3657 non-null int64
발생년월일시 3657 non-null int64
발생분 3657 non-null int64
주야 3657 non-null object
요일 3657 non-null object
사망자수 3657 non-null int64
사상자수 3657 non-null int64
중상자수 3657 non-null int64
경상자수 3657 non-null int64
부상신고자수 3657 non-null int64
발생지시도 3657 non-null object
발생지시군구 3657 non-null object
사고유형_대분류 3657 non-null object
사고유형_중분류 3657 non-null object
사고유형 3657 non-null object
법규위반_대분류 3657 non-null object
법규위반 3657 non-null object
도로형태_대분류 3657 non-null object
도로형태 3657 non-null object
가해자_당사자종별_대분류 3657 non-null object
가해자_당사자종별 3657 non-null object
피해자_당사자종별_대분류 3657 non-null object
피해자_당사자종별 3657 non-null object
발생위치X_UTMK 3657 non-null float64
발생위치Y_UTMK 3657 non-null float64
경도 3657 non-null float64
위도 3657 non-null float64
dtypes: float64(4), int64(8), object(15)
memory usage: 771.5+ KB이후에는 null을 확인한다.
df.isnull().sum()
발생년 0
발생년월일시 0
발생분 0
주야 0
요일 0
사망자수 0
사상자수 0
중상자수 0
경상자수 0
부상신고자수 0
발생지시도 0
발생지시군구 0
사고유형_대분류 0
사고유형_중분류 0
사고유형 0
법규위반_대분류 0
법규위반 0
도로형태_대분류 0
도로형태 0
가해자_당사자종별_대분류 0
가해자_당사자종별 0
피해자_당사자종별_대분류 0
피해자_당사자종별 0
발생위치X_UTMK 0
발생위치Y_UTMK 0
경도 0
위도 0
dtype: int64널 값은 없지만 필요없는 데이터가 있어 drop보다 필요한 데이터 위주로 프레임을 다시 만들어준다.
df = df[['발생년월일시','사망자수','주야','요일','발생지시도','발생지시군구','경도','위도']]이후 info를 보면 발생년월일시가 int형식인 것을 알 수 있다.
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3657 entries, 0 to 3656
Data columns (total 8 columns):
발생년월일시 3657 non-null int64
사망자수 3657 non-null int64
주야 3657 non-null object
요일 3657 non-null object
발생지시도 3657 non-null object
발생지시군구 3657 non-null object
경도 3657 non-null float64
위도 3657 non-null float64
dtypes: float64(2), int64(2), object(4)
memory usage: 228.6+ KBdate로도 바꿔주고 주/야간, 요일, 지역 데이터를 한글에서 숫자로 바꿔준다.
t_map = {
'주' : 0,
'야' : 1
}
d_map = {
'월' : 1,
'화' : 2,
'수' : 3,
'목' : 4,
'금' : 5,
'토' : 6,
'일' : 7
}
r_map = {
'강원' : 'Gangwon',
'경기' : 'Gyeonggi',
'경남' : 'Gyeongsangnam',
'경북' : 'Gyeongsanbuk',
'광주' : 'Gwangju',
'대구' : 'Daegu',
'대전' : 'Daejeon',
'부산' : 'Busan',
'서울' : 'Seoul',
'세종' : 'Sejong',
'울산' : 'Ulsan',
'인천' : 'Incheon',
'전남' : 'Jeollanam',
'전북' : 'Jeollabuk',
'제주' : 'Jeju',
'충남' : 'Chungcheongnam',
'충북' : 'Chungcheongbuk'
}
df['주야'] = df['주야'].map(t_map)
df['요일'] = df['요일'].map(d_map)
df['발생지시도'] = df['발생지시도'].map(r_map)
df.head()
df['발생년월일시'] = df['발생년월일시'].apply(lambda x: pd.to_datetime(str(x),format='%Y%m%d%H'))
db.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3657 entries, 0 to 3656
Data columns (total 8 columns):
발생년월일시 3657 non-null datetime64[ns]
사망자수 3657 non-null int64
주야 3657 non-null int64
요일 3657 non-null int64
발생지시도 3657 non-null object
발생지시군구 3657 non-null object
경도 3657 non-null float64
위도 3657 non-null float64
dtypes: datetime64[ns](1), float64(2), int64(3), object(2)
memory usage: 228.6+ KB이후 일시단위는 필요 없기 때문에 버려준다.
df['발생년월'] = df['발생년월일시'].dt.strftime('%Y%m')
df.drop(['발생년월일시'],axis=1, inplace=True)
db.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3657 entries, 0 to 3656
Data columns (total 8 columns):
사망자수 3657 non-null int64
주야 3657 non-null int64
요일 3657 non-null int64
발생지시도 3657 non-null object
발생지시군구 3657 non-null object
경도 3657 non-null float64
위도 3657 non-null float64
발생년월 3657 non-null object
dtypes: float64(2), int64(3), object(3)
memory usage: 228.6+ KB데이터프레임을 보고 변환이 잘 되었는지 확인한다.
df.head()
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
sns.set_style('darkgrid')그래프 그릴 준비를 한다.
먼저 발생월에 따른 그래프를 그려본다.
df_time = df.groupby(['발생년월','주야'],as_index=False).sum()
df_time.head()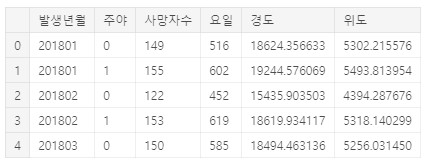
plt.figure(figsize=(13,6))
plt.title('timezone graph')
sns.lineplot(x='발생년월', y='사망자수',data=df_time, hue='주야')
sns.scatterplot(x='발생년월', y='사망자수',data=df_time, hue='주야')
plt.xlabel('month')
plt.ylabel('count')
0이 주간이고 1이 야간이다. 대체적으로 상반기보다 하반기가 사망사고가 많다.
df_day = df.groupby(['요일'],as_index=False).sum()
df_day.head()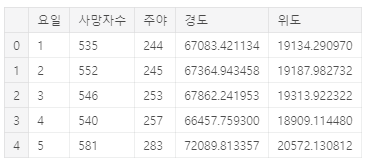
요일별로도 묶어서 그려본다.
plt.figure(figsize=(13,6))
plt.title('timezone graph')
sns.barplot(x='요일', y='사망자수',data=df_day)
plt.xlabel('day')
plt.ylabel('count')
대체적으로 비슷한 양상을 보이는데 금-토에 조금 더 많은 것을 알 수 있다.
df_region = df.groupby(['발생지시도','주야'],as_index=False).sum()
df_region.head()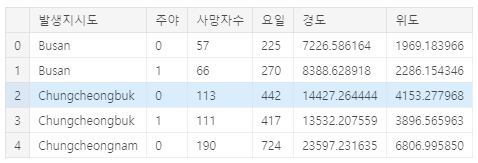
시도별로도 묶어서본다. 인구수 대비한 비율이 나올거 같지만 한 번 해본다.
plt.figure(figsize=(25,6))
plt.title('region graph')
sns.barplot(x='발생지시도', y='사망자수',data=df_region, hue='주야')
plt.xlabel('region')
plt.ylabel('count')
경기도가 압도적이다. 하지만 못써먹은 데이터를 보면 (자꾸 에러가 ㅠㅠ) 인구수 60만의 제주가 인구수 140만의 광주랑 비슷한 사망률을 보인다.
"행정구역(시군구)별",총인구수 (명)
"all",51826059
"Seoul",9765623
"Busan",3441453
"Daegu",2461769
"Incheon",2954642
"Gwangju",1459336
"Daejeon",1489936
"Ulsan",1155623
"Sejong",314126
"Gyeonggi",13077153
"Gangwon",1543052
"Chungcheongbuk",1599252
"Chungcheongnam",2126282
"Jeollabuk",1836832
"Jeollanam",1882970
"Gyeongsanbuk",2676831
"Gyeongsangnam",3373988
"Jeju",667191위경도 좌표가 있으니 매핑도 한 번 해본다.
import folium
folium.Map(location=[36.4,127.16],zoom_start=6.5)
accident_circle = folium.Map(location=[36.4,127.16],zoom_start=6.5)
for lat,lng,num in zip(df.위도, df.경도,range(3000)):
folium.CircleMarker([lat,lng],radius=1,fill=True).add_to(accident_circle)
accident_circle원래 num을 지우고 위/경도를 다 돌아야하는데 너무 많아서 kaggle 상에서 안뜬다.
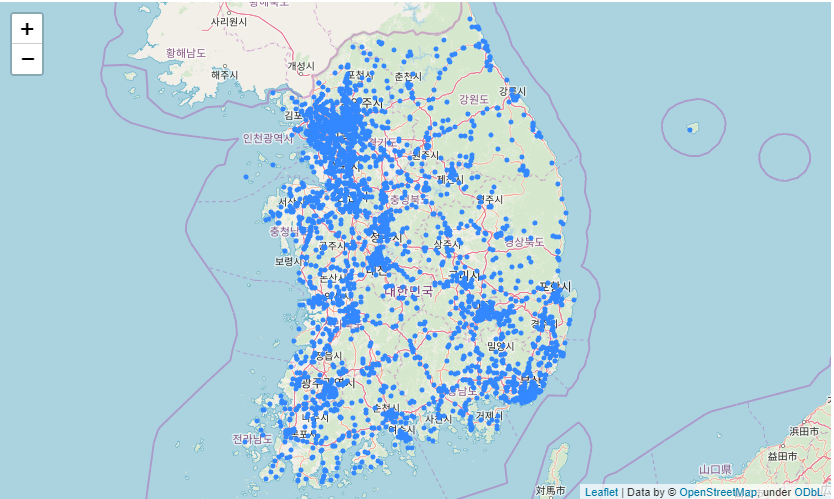

대충보면 수도권상에 엄청 많은 것을 알 수 있다. 제주도의 경우 고르게 분포되어 있는데 주로 해안도로쪽에서 사망사고가 일어난다.
- 이를 이용해서 사망사고가 잦은 도로를 알아낼 수 있을 것이다
- 인구수 대비 사망사고가 많은 지역은 별도의 교육을 할 수 있을 것이다 (다음에 시간나면 해보자)
- 월별 양상을 더 살펴보는 것도 좋을 것 같다 (어디에서 여름에 사고가 많이 나는지, 주간에 나는지 야간에 나는지)
'Python > DeepLearning' 카테고리의 다른 글
| Table Detection using Deep Learning 따라하기 (0) | 2019.05.27 |
|---|---|
| 가상환경에서 tesseract 실행하기 (0) | 2019.05.22 |
| 왜 machine learning에서는 Normal Distributions를 사용할까? (3) | 2019.05.16 |
| Tensorflow 기반 딥러닝 핵심과 활용 (0) | 2019.05.15 |
| TensorFlow 교육 - 2일차 (0) | 2019.05.14 |


