2019/05/09 - [계약/SIDE] - Statistical Process Control (SPC)
갑자기 하늘에서 떨어져 내게 온 SPC를 세미 체험해보기 위해 Python을 켰다. SPC에 관련된 내용은 이전 글을 읽자. 그리 어려운 내용은 아니고 그저 내가 원하는 조건에서 벗어나는 친구들이 생기는지 생기지 않는지 감시하는 용도로 간단히 생각하면 될 듯 하다. Python님은 못가진거빼고 다 가지고 계시기 때문에 검색을 통해 라이브러리를 찾아본다. 역시 사귄지 얼마안된 내 친구 파이썬은 원하는 라이브러리가 있었다.
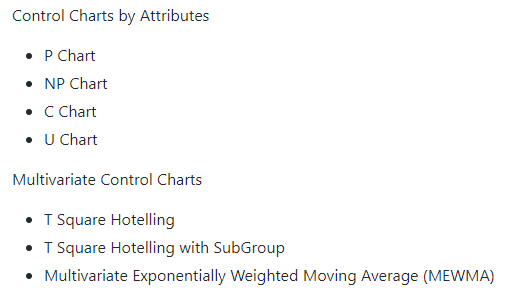
감사한 분에게 인사드리며 pyspc 라이브러리는 다음 주소로 찾아가면 된다. 제공하는 차트는 아래와 같다.
pip install pyspc마법의 주문으로 새로운 라이브러리를 맞이해준다.
from pyspc import *
a = spc(pistonrings) + ewma()
print(a)간단하게 내장된 테스트를 진행하여 라이브러리가 잘 실행되는지 확인해준다.

이 친구 겉으로는 얌전한 척 하더니 sample이 거듭되자 range 밖의 값을 내뱉는다. EWMA는 지수가중 이동평균 모형으로 가중치를 가진 모형이다. 통계 전공이 아니므로 잘 모르지만 간단하게 생각해서 t번째 시도를 할 때 t-1번째가 t에게 영향을 많이줄까 t-100번째가 t에게 영향을 많이 줄까? 당연히 t-1번째일 것이다. 그런 개념으로 접근하면 될 것 같다. (저도 잘 모름) 일단 내가 원하는 데이터로 그래프를 그려보기 이전에 p-chart를 그리기 위해 어떤 데이터가 필요한지 생각해보자.
p-chart의 식은 다음과 같다.


샘플데이터 중 하나인 circuits.csv로 생각해보자.
| 샘플 | 결함(부적합) |
| 100 | 21 |
| 100 | 24 |
| 100 | 16 |
| ... | ... |
이런 데이터를 가지고 있다. 먼저 p를 구한다.
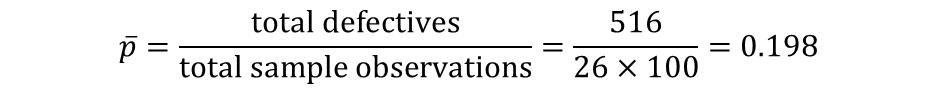
0.198이란 수가 나온다. 이 데이터의 평균은 0.198인 것이다. 이제 UCL과 LCL을 구해본다.

과연 계산 결과가 맞을까? 파이썬으로 그려본다.
from pyspc import *
import numpy
a = spc(circuits) + p() + rules()
print(a)
다른 P-chart도 그려본다. chanjuice.csv라는 파일이 있다.


이젠 쉽게 생각할 수 있다.
다음은 c-chart이다. c차트의 공식은 다음과 같다.
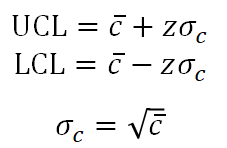
- pip로 다운받는 pyspc에 에러가 있다.
def plot(self, ax, data, size, newdata=None):
print(data.T)
sizes, data = data.T
if self.size == 1:
sizes, data = data, sizes
# the samples must have the same size for this charts
assert np.mean(sizes) == sizes[0]
cbar = np.mean(data)
lcl = cbar - 3 * np.sqrt(cbar)
ucl = cbar + 3 * np.sqrt(cbar)
#
# ax.plot([0, len(data)], [cbar, cbar], 'k-')
# ax.plot([0, len(data)], [lcl, lcl], 'r:')
# ax.plot([0, len(data)], [ucl, ucl], 'r:')
# ax.plot(data, 'bo-')
return (data, cbar, lcl, ucl, self._title)라이브러리 내에 c.py를 열어보면 plot 함수에 들어가는 인자가 (self, ax, data, size, newdata=None)으로 되어 있는데 여기서 ax를 제거해주어야 한다. 데이터가 하나씩 밀려서 들어간다.
def plot(self, data, size, newdata=None):
print(data.T)
sizes, data = data.T
if self.size == 1:
sizes, data = data, sizes
# the samples must have the same size for this charts
assert np.mean(sizes) == sizes[0]
cbar = np.mean(data)
lcl = cbar - 3 * np.sqrt(cbar)
ucl = cbar + 3 * np.sqrt(cbar)
#
# ax.plot([0, len(data)], [cbar, cbar], 'k-')
# ax.plot([0, len(data)], [lcl, lcl], 'r:')
# ax.plot([0, len(data)], [ucl, ucl], 'r:')
# ax.plot(data, 'bo-')
return (data, cbar, lcl, ucl, self._title)
이렇게 바꾸면 아주 잘 실행된다. c차트의 공식을 이용하여 값을 먼저 구해본다.
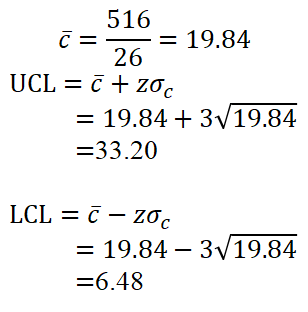
from pyspc import *
import numpy
import pandas
a = spc(circuits) + c() + rules()
print(a)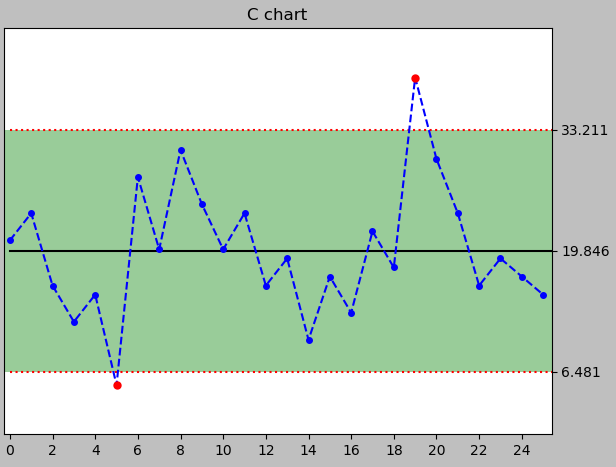
python이 계산을 다 해주더라도 직접 한 번씩 구해보는게 좋다.
이제 variable 차트를 그려본다.

mean chart는 xbar_rbar를 사용하면된다.

sample data인 diameter.csv를 10개만 사용하여 공식을 대입해본다.
번거로워서 엑셀로 한번에 정리했다.

근데 얘는 사용하는 규칙이 조금 다르다.
| A2 = [0, 0, 1.880, 1.023, 0.729, 0.577, 0.483, 0.419, 0.373, 0.337, 0.308] |
이걸 사용한다..

from pyspc import *
import numpy
import pandas
a = spc(circuits) + xbar_rbar() + rules()
print(a)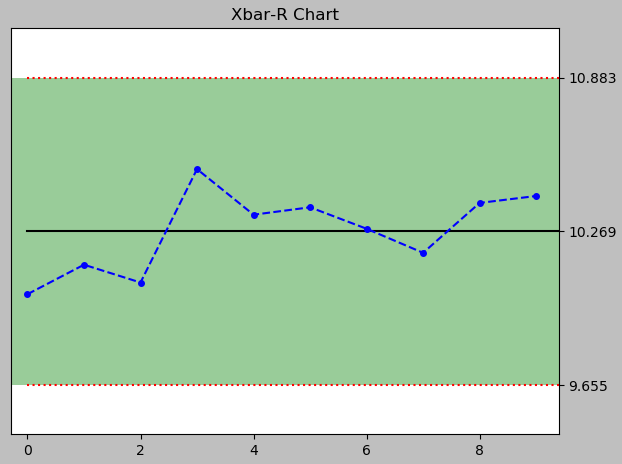
R-bar 차트도 그려보자.
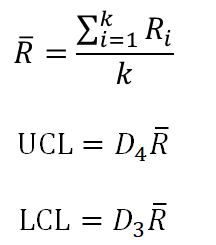
데이터는 똑같은거 쓸거임~~! 어려울 거 없이 D4, D3만 알아내서 대입해주면된다.
| D3 = [0, 0, 0, 0, 0, 0, 0, 0.076, 0.136, 0.184, 0.223] |
| D4 = [0, 0, 3.267, 2.575, 2.282, 2.115, 2.004, 1.924, 1.864, 1.816, 1.777] |
from pyspc import *
import numpy
import pandas
a = spc(diameter) + rbar() + rules()
print(a)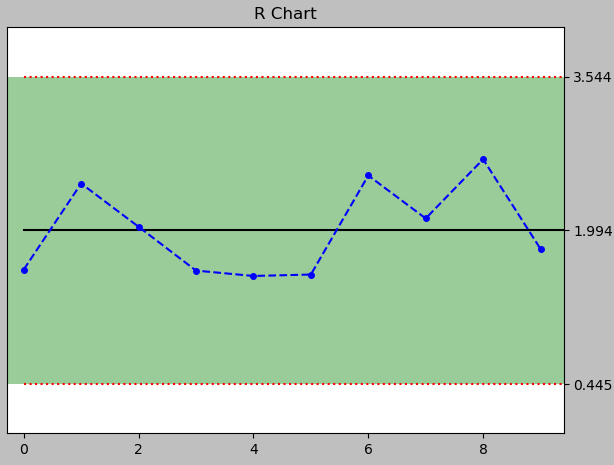
여기까지하면 기본적인 4개의 그래프는 다 그려보았다.
'Python > Default' 카테고리의 다른 글
| Python 교육 1일차 (0) | 2019.05.30 |
|---|---|
| Python PDF extract tool 정리 (0) | 2019.05.29 |
| CentOS7에서 Oracle 연동 오류 (0) | 2019.04.16 |
| CentOS 환경에 Python3 설치 후 나타나는 에러 수정 (0) | 2019.04.16 |
| NLTK 라이브러리 사용 중간에 멈춤 현상 (0) | 2019.02.21 |


