- 반드시 사용자의 이름은 영어여야 한다 (윈도우 환경)
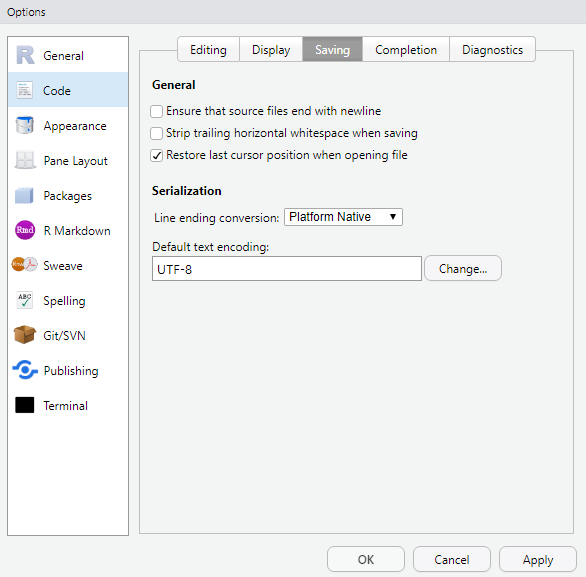
- R 설정 중 한글이 깨지 않기 위해 인코딩을 변경해야 한다.
tool > global options > codes > saving
먼저 세 과목의 합계를 출력해보자.
kor <- 90
eng <- 70
mat <- 95
tot <- kor+eng+mat
print("세 과목 합계는 ")
print(tot)결과값은 다음과 같다.
> kor <- 90
> eng <- 70
> mat <- 95
> tot <- kor+eng+mat
> print("세 과목 합계는 ")
[1] "세 과목 합계는 "
> print(tot)
[1] 255ctrl + L을 누르면 출력창이 깨끗해진다.
R은 데이터를 알아서 관리해준다.
> mode(cnum)
[1] "character"
> num <- 1
> mode(num)
[1] "numeric""1"과 1은 서로 다른 존재이다.
> kor <- 95
> above90 <- kor>=90 #kor 값이 90 이상인가?
> below90 <- kor< 90 #kor 값이 90 미만인가?
> print(above90)
[1] TRUE
> print(below90)
[1] FALSEboolean 값도 저장할 수 있다.
> today1 <- Sys.Date()
> print(today1)
[1] "2019-06-05"
> today2 <- Sys.time()
> print(today2)
[1] "2019-06-05 09:37:36 KST"날짜는 시스템함수를 사용한다.
- 함수가 뭐죠?
복잡한 계산을 알아서 해주는 거임.
- 패키지는 뭐죠?
함수들의 모음임
- 패키지 다운받는 법
install 눌러서 받는다.

꺄 함수 샤용해보장~~ 마장마장~~
한 과목 성적에 대하여 반 총점과 반 평균을 구하고 반에서 해당 과목의 최고 점수 또는 최저 점수를 구하는 함쑤
> score <- c(80, 90, 70, 65, 55, 30, 60, 90, 88, 100, 78, 30, 55, 61, 89, 68, 78, 70, 88, 82)
> sumScore <- sum(score)
> score <- c(80, 90, 70, 65, 55, 30, 60, 90, 88, 100, 78, 30, 55, 61, 89, 68, 78, 70, 88, 82)
> sumScore <- sum(score)
> avgScore <- mean(score)
> cat("총점 = ", sumScore, "평균 점수 = ", avgScore)
총점 = 1427 평균 점수 = 71.35또 해봐요
> score <- c(80, 90, 70, 65, 55, 30, 60, 90, 88, 100, 78, 30, 55, 61, 89, 68, 78, 70, 88, 82)
> sumScore <- sum(score)
> avgScore <- mean(score)
> midScore <- median(score)
> stdNum <- length(score)
> maxScore <- max(score)
> minScore <- min(score)
> cat("총점 = ", sumScore, "평균 점수 = ", avgScore)
총점 = 1427 평균 점수 = 71.35
> cat("평균 점수 = ", avgScore, "가운데 점수 = ", midScore, "\n")
평균 점수 = 71.35 가운데 점수 = 74
> cat("최고 점수 = ", maxScore, "최저 점수 = ", minScore,"\n")
최고 점수 = 100 최저 점수 = 30 source 누르면 이렇게 나와요
총점 = 1427 평균 점수 = 71.35평균 점수 = 71.35 가운데 점수 = 74
최고 점수 = 100 최저 점수 = 30 실습인 판매 실적 데이터 처리 해봅시다.
sales <- c(80, 90, 70, 65, 55, 30, 60, 90, 88, 100, 76, 30)
sumSales <- sum(sales)
meanSales <- mean(sales)
maxSales <- max(sales)
minSales <- min(sales)
topSales <- which.max(sales)
downSales <- which.min(sales)
sortSales <- sort(sales)
cat ("판매 총액 = ", sumSales, "월평균 판매 금액 = ", meanSales, "\n")
cat ("월 최대 판매 금액 = ", maxSales, "월 최소 판매 금액 = ", minSales, "\n")
cat ("최대 판매한 달 = ", topSales, "최소 판매한 달 = ", downSales, "\n")
cat ("판매 금액이 높은 순으로 정렬하기 = ", sortSales, "\n")이거에욤
총점 = 1427 평균 점수 = 71.35평균 점수 = 71.35 가운데 점수 = 74
최고 점수 = 100 최저 점수 = 30
판매 총액 = 834 월평균 판매 금액 = 69.5
월 최대 판매 금액 = 100 월 최소 판매 금액 = 30
최대 판매한 달 = 10 최소 판매한 달 = 6
판매 금액이 높은 순으로 정렬하기 = 30 30 55 60 65 70 76 80 88 90 90 100 아이 좋아~~! 근데 높은순 아닌데 이렇게 바꾸면 됨
sortSales <- sort(sales, decreasing = TRUE)
판매 금액이 높은 순으로 정렬하기 = 100 90 90 88 80 76 70 65 60 55 30 30 데이터를 묶어서 처리하는 것은 매우 중요하다. R에서는 데이터를 묶어서 처리하는 데에 두 가지 방법이 있다.
- 동일한 유형의 데이터를 묶어서 관리 (column형)
- 한 가지 데이터를 묶어서 관리 (row형)
'미분류 > R' 카테고리의 다른 글
| Understanding data science: classification with neural networks in R (0) | 2019.06.12 |
|---|---|
| Understanding data science: clustering with k-means in R (0) | 2019.06.11 |
| Understanding data science: dimensionality reduction with R (0) | 2019.06.04 |
| Understanding data science:designing useful features with R (0) | 2019.06.03 |
| Understanding data science: feature extraction with R (0) | 2019.06.03 |



