neural networks는 일반적으로 data science에서 사용한다. feature vector를 그룹화해서 클래스로 분류하고, 새로운 데이터를 라벨링해준다. 엔지니어링에서는 장비의 상태를 진단하고 정상인지 아닌지 식별하는데 사용된다. 저번에 추출한 feature를 사용하여 베어링의 상태를 알아낼 수 있도록 훈련시켜본다.
The classification problem
14개의 feature로 베어링의 상태를 알아내보자. k-means clustering를 사용하였을 때에는 7가지의 상태를 알려주고 있다.
- green: “early” (initial run-in of the bearings)
- blue: “normal”
- yellow: “suspect” (health seems to be deteriorating)
- red: “failure.b2”, “failure.inner” (b3), or “failure.roller” (b1 and b4)
- salmon: “stage2” (secondary failure of b4)
그래프로 살펴보자.
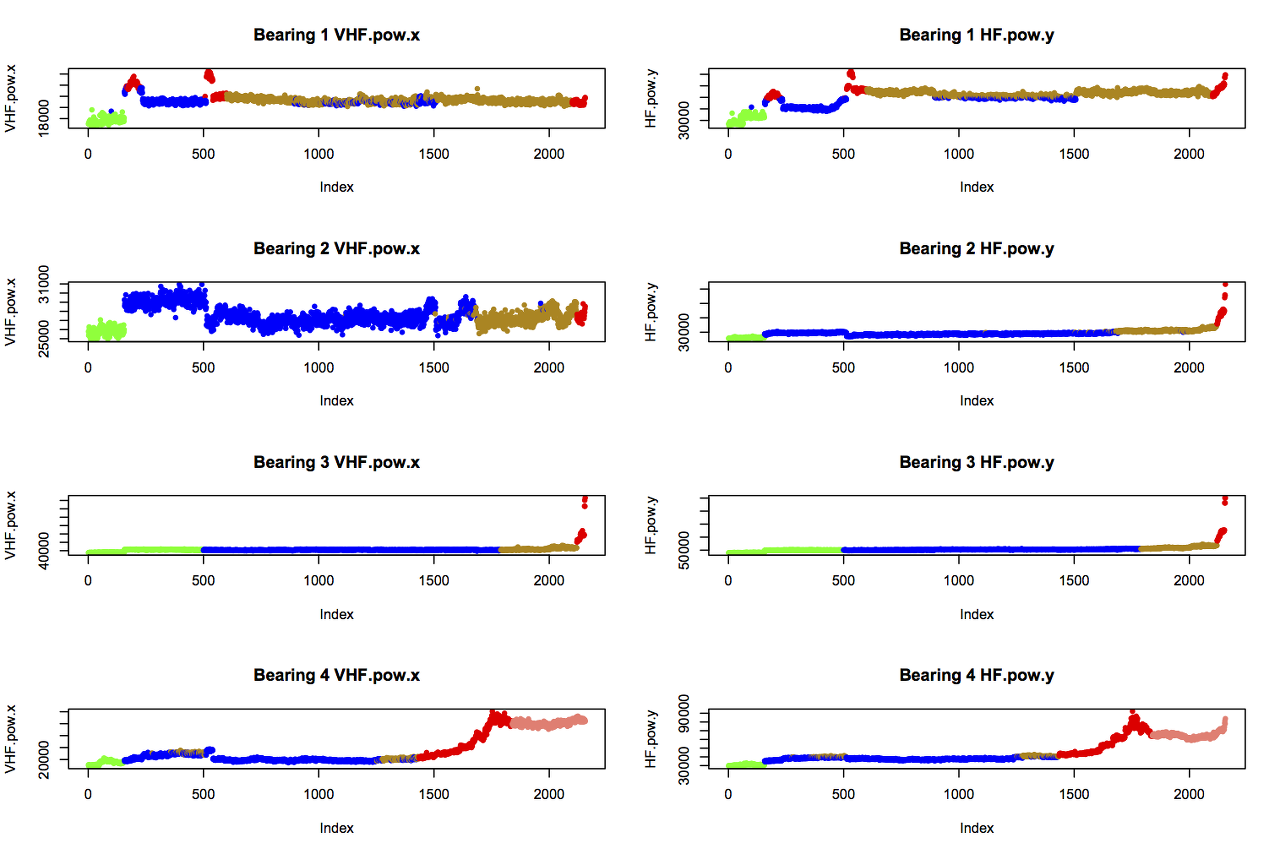
k-means를 했다면 data가 있을 것이다. 없으면 만들자.
basedir <- "/Users/vic/Projects/bearings/bearing_IMS/1st_test/"
data <- read.table(file=paste0(basedir, "../all_bearings_best_fv.csv"), sep=",", header=TRUE)
# Read in the best kmeans model. Straight after running kmeans.R the
# filename will be "kmeans.obj", but this is the best model I found.
load(paste0(basedir, "../../models/best-kmeans-12-0.612.obj"))
## Adjust the class labels as a result of k-means
# Cluster 2 should be labelled "suspect"
data[best.kmeans$cluster==2,2] <- "suspect"
# Cluster 3 should be labelled "normal"
data[best.kmeans$cluster==3,2] <- "normal"
# Cluster 9 datapoints labelled "early" should be "normal"
data[((best.kmeans$cluster==9)&(data$State=="early")),2] <- "normal"
# b1 failure looks like a rolling element failure
data[data$State=="failure.b1", 2] <- "failure.roller"
data[((best.kmeans$cluster==11)&(data$State=="unknown")),2] <- "failure.roller"
data[((best.kmeans$cluster==11)&(data$State=="normal")),2] <- "suspect"
data[((best.kmeans$cluster==10)&(data$State=="unknown")),2] <- "early"
# Cluster 6 should all be "normal"
data[best.kmeans$cluster==6,2] <- "normal"
## Now plot to check the result
# use the same colours for states as before
cols <- do.call(rbind, Map(function(s)
{
if (s=="early") "green"
else if (s == "normal") "blue"
else if (s == "suspect") "darkgoldenrod"
else if (s == "stage2") "salmon"
else if (s == "unknown") "black"
else "red"
}, data$State))
# plot each bearing changing state
par(mfrow=c(2,2))
for (i in 1:4)
{
s <- (i-1)*2156 + 1 # 2156 datapoints per bearing
e <- i*2156
plot(best.kmeans$cluster[s:e], col=cols[s:e], ylim=c(1,k), main=paste0("Bearing ", i), ylab="Cluster")
}
# Now save
write.table(data, file=paste0(basedir, "../all_bearings_relabelled.csv"), sep=",", row.names=FALSE)
작성한 파일을 불러온다.
basedir <- "../bearing_IMS/1st_test/"
data <- read.table(file=paste0(basedir, "../all_bearings_relabelled.csv"), sep=",", header=TRUE)Artificial Neural Networks(ANNs)
ANN은 뇌에서 뉴런의 구조와 학습 과정을 모방함으로써 데이터의 패턴을 학습할 수 있다. engineering problems에 대해 폭넓게 사용되고 있다. 엔지니어링 문제는 단순한 형태로 드물게 발생하기 때문에 ANN을 사용하기에 적합하다. 하지만 네트워크를 구현하는 것은 어려운 일미여 정확한 네트워크를 만들기 위해서는 몇 번의 시행 착오가 필요하다.
표준 ANN은 feature 레이어, hidden 레이어, 출력 레이어 총 3가지로 구성된다. 베어링 데이터 세트에는 14개의 feature와 7개의 라벨이 정해져 있으므로 자동으로 입력은 14, 출력은 7개로 정해진다.
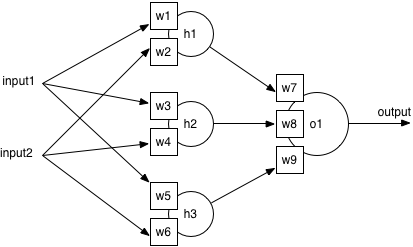
모든 뉴런은 구조가 동일하며 sum unit와 function unit을 가지고 있다. 이제 뉴런이 입력을 어떻게 출력으로 변환하는지에 대해 알아보자
What does a neuron do?
input neuron은 input들을 합쳐 하나의 single value를 만든다. 이 값을 x라고 한다. 이 input은 function을 거쳐 ouput이 된다.
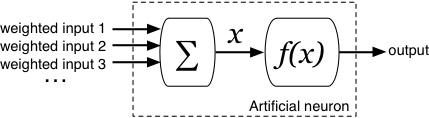
neurons에 사용되는 수많은 function들이 있지만 가장 일반적인 함수는 sigmoid function이다. 얘는 아래와 같이 표현된다.
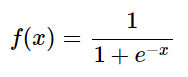
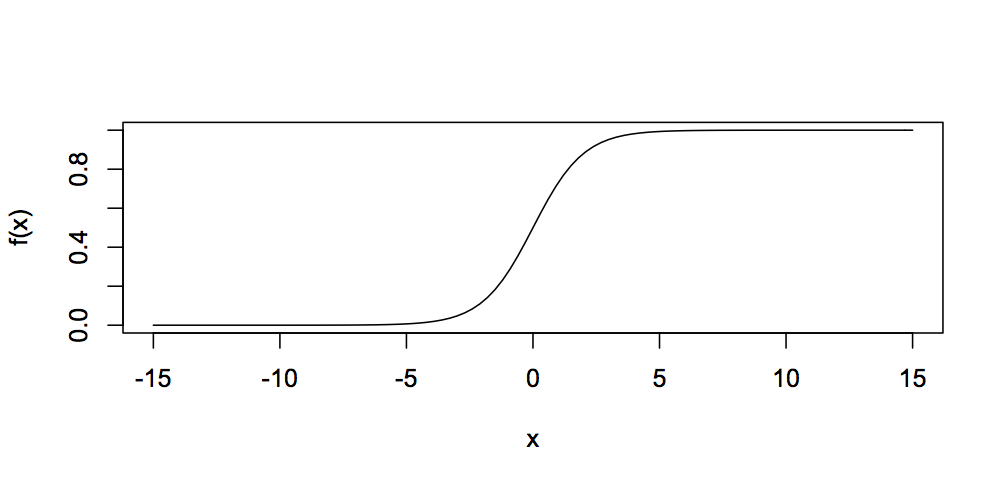
언제나 출력값이 0에서 1 사이인 것을 볼 수 있다. 그렇기 때문에 output neuron은 항상 0에서 1사이의 값을 도출해낸다. 이 정보를 통해 output neuron에서 나오는 값의 결과를 계산할 수 있다. 임의의 neuron o1을 살펴보자.
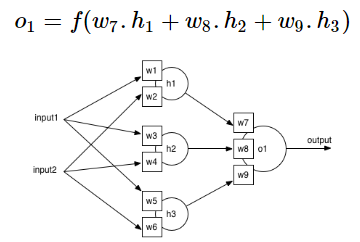
input의 계산법은 이렇다.
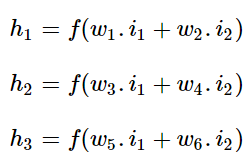
이 예제는 single output neuron의 예제를 보여주고 있다. 그래서 베어링에 문제가 있는지 없는지 밖에 판단하지 못하는 2진 분류만이 가능하다. 실제 네트워크는 7개의 아웃풋을 원하므로 sigmoid function을 이용하여 0과 1 사이의 값을 갖는 ouput을 나타내야 한다. 그 중 winner를 선정하여 class를 정해주어야 하는 것이다.
Training the network
하지만 모든 뉴런이 동일하다면 어떻게 판단해야 할까? 이는 위의 식에 있는 w(가중치)로 판단할 수 있다. feature는 가중치를 가질 수 있으며 뉴런의 합계에 따라 기여도가 달라진다. 실제로 한 뉴런에는 큰 가중치를 주고 다른 뉴런에는 작은 가중치를 준다면 작은 가중치 쪽은 큰 영향을 끼치지 못할 것이다.
sigmoid function는 입력이 임계값을 넘었을 때 neuron의 아웃풋을 0에서 1사이의 값으로 변환해준다. 예를 들어 큰 가중치와 큰 인풋이 들어왔을 때, 중간의 가중치와 큰 인풋이 들어왔을 때가 있다. 네트워크 학습의 목표는 정확성을 높이기 위해 최상의 가중치를 찾는 것이다.
트레이닝에 사용되는 알고리즘은 backpropagation(역전파)이다. 데이터의 샘플을 네트워크에 넣어 추측한 결과와 실제 값을 비교하여 오류를 통해 가중치를 업데이트 시킨다. 예를 들어 네트워크가 예측한 값이 "normal"이고 실제 값이 "early"라면 normal의 weight를 줄여 "early" 로 예측할 수 있게 만들어주는 것이다. 이후 다시 측정해보면 정확도가 조금 더 높아지는 것을 확인할 수 있다.
training epoch는 샘플 데이타가 얼마나 반복되었는지를 뜻한다. 가중치가 안정된 상태 값에 도달하거나 최대 반복 횟수에 도달할 때까지 데이터는 여러번 반복 사용된다. 한 가지 문제점이 있다면 overfit이 존재한다는 것이다. 이는 과적합이라고 부르며 몇 몇의 데이터에만 정확도를 보여주고 다른 데이터에는 좋지 않은 정확도를 보여주는 것을 뜻한다. 이 문제를 극복하기 위해서는 전체 데이터 세트를 train set, test set로 나누어 train set으로 훈련 이후 test set으로 정확도를 측정해야 한다. test set의 정확도가 그 네트워크의 정확도가 된다.
Using nnet in R
이제 R에서 nnet 패키지를 이용해 ANN을 구현해보자. 얘는 1개의 hidden layer와 sigmoid function을 사용한다. 이 것을 변경하고 싶다면 parameter를 변경하면 된다.
첫번째로 input에 베어링의 state를 넣는다. 데이터는 베어링의 이름을 가지고 있으므로 1 컬럼을 제외하고 넣어준다.
nnet(State ~ ., data=data[,-1])
가중치를 조절하기 위해 적당한 값을 넣고(이는 아주 작은 값) epoch를 정해준다.
nnet(State ~ ., data=data[,-1], decay=5e-4, maxit=200)
다음은 사용할 뉴런의 수를 결정한다. 몇 가지 규칙을 가지고 있으나 2에서 30사이의 모든 숫자를 사용하여 가장 높은 정확도를 표출해내는 개수만큼을 사용할 것이다. 또한 시작할 때에 가중치가 무작위로 할당되므로 동일한 집합을 3번 훈련하여 평균값을 얻는 것이 좋다.
Feature Vector scale
feature로 뽑은 친구들은 각자 다른 범위를 가지고 있다. x-axis는 -2.54에서 2.16이지만 VHF의 경우 16,677에서 166,444까지이다. 적합한 가중치를 찾으려면 서로 다른 범위내에서 움직여야 한다. 이를 돕기 위해 nnet는 0.5로 설정된 rang을 다음과 같이 설정해야한다.
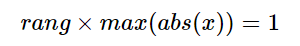
하지만 이렇게 하면 또 작은 값에는 맞지 않을 것이므로 다음과 같이 적용한다.
ann <- nnet(State ~ ., data=data[,-1], size=h, rang=(1/max(data[,-c(1,2)])), decay=5e-4, maxit=200)
data set을 normalized 하여 사용할 수도 있다.
사용 이전에 train set을 만든다.
train.pc <- 0.7
train <- vector()
for (state in unique(data$State))
{
all.samples <- data[data$State==state,]
len <- length(all.samples[,1])
rownums <- sample(len, len*train.pc, replace=FALSE)
train <- c(train, as.integer(row.names(all.samples)[rownums]))
}
# Write to file for future use
write.table(train, file=paste0(basedir, "../train.rows.csv"), sep=",")
# Compare the balance of classes
table(data$State)
table(data[train,"State"])
normed <- cbind(data[,1:2], as.data.frame(lapply(data[,-c(1,2)], function(col) { col / max(abs(col)) })))
ann <- nnet(State ~ ., data=normed[,-1], size=h, decay=5e-4, maxit=200)이제 네트워크를 사용하여 결과를 살펴본다. h(hidden neuron)을 2에서 30개롤 조정하였고 3번씩 runs해보았다.
'미분류 > R' 카테고리의 다른 글
| Understanding data science: more classification techniques (0) | 2019.06.13 |
|---|---|
| Understanding data science: clustering with k-means in R (0) | 2019.06.11 |
| R 기본 (추가 중) (0) | 2019.06.05 |
| Understanding data science: dimensionality reduction with R (0) | 2019.06.04 |
| Understanding data science:designing useful features with R (0) | 2019.06.03 |



